Introduction
Whether you are running a small water plant, a sewage plant, an offshore production platform, pipeline systems, a distillery (commercial one!), there will be systems in place to provide safety functions and shutdown actions. These Emergency Shutdown Systems (ESDs) are designed to ensure the process enters a known safe state without the need for human intervention. The systems can have input devices from Pressure Transmitters, Level Gauges, Vibration Sensors, Temperature Sensors etc., and can have outputs controlling valves, relays, contactors, warning lights, sirens etc.; basically, anything can come into a system, and anything can go out of a system.
The systems also need to be designed in such a way that if field wiring, i.e., the cabling between the end devices and the system is cut, or the instrument fails, it still enters a safe state.
As these systems have evolved with each generation of modern technology, they have become larger and can handle thousands of input and output devices, and the bit that runs the software in the middle can now be spread across multiple processing units, that can be located next to each other or on another part of the plant.
This now introduces a problem, how can we ensure the system fails to a safe state when the individual processing units can no longer talk to each other due to the communication link having being damaged? It is possible to engineer the system to increase the reliability and availability by including redundant components that hot swap on fault detection, or providing multiple communication paths on diverse routes, but what if it does go wrong and all your communication links have been lost? That's when you need to think about building a fail safe mechanism at the software level. This article hopes to explain the basic principle employed on a real world system. A system which is located in the middle of the North Sea, on an oil production platform, where if it all goes wrong, you don't have anywhere to run to.
Background
There are many different type of systems, from various manufacturers, they all use various twists on a similar theme, and use different terminology to talk about the same thing. In this article, the implementation of the fail safe software mechanism is built into an Emerson DeltaV, Distributed Control System (DCS). It doesn't really matter who makes the system, all we are interested in is how can a system like this be programmed to cater for communication failures.
The system in question comprises a number of Logic Solvers. A Logic Solver is the programmable element that reads and writes the input and output signals from and to the field devices. This system actually currently has 9 Logic Solvers, all communicating with each other. Each Logic Solver has a number of inputs and outputs allocated, and each Logic Solver can also read and write to each other's inputs and outputs. The system can also run the software relating to any given input or output in a completely different Logic Solver to the one that actually has the real world device connected.
This system is also fully integrated, which means that both the Process Safety System (PSS) or ESD and Process Control System (PCS) are contained within the same hardware.
We will not be looking at the specific code, but the generic blocks and logic used to obtain the desired result. This makes it easier to understand, and makes the philosophy transportable onto other branded systems.
Shall we begin?
So What is a Logic Solver
To start with, let's look at the components of the Logic Solver and what we can do at the hardware level to increase the reliability and availability of the system. The block diagram below is a typical logic solver cabinet used on the system:
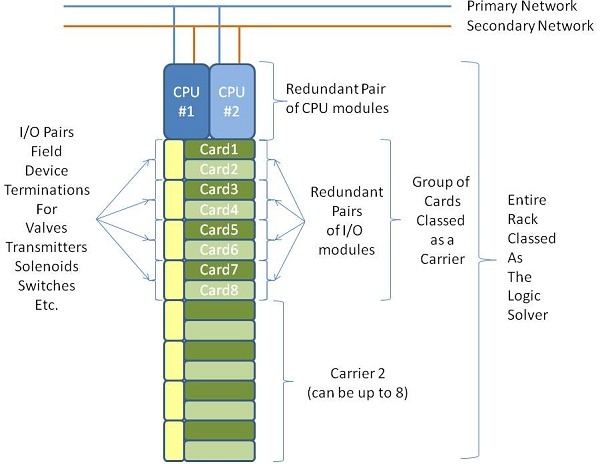
The Logic Solver is built with multiple component redundancy. The components automatically switch duty from Online to Standby in the event of fault detection. The only common elements are the terminal rails that connect the field devices. This means the Field IO is Simplex, but everything at the system level is Duplex.
There are a pair of Central Processing Units (CPUs), these are the brains that run the software modules, and perform all the communication with the field input/output (IO) modules, and also the communications with other parts of the system. In the event of a hardware error, these switch over, and the faulty one goes 'offline'. This transfer is inherent to the system, completely transparent, and no impact is detected by the system. The online CPU can be pulled out while in service, and the standby will automatically pickup the duty.
The CPUs are connected to a Carrier (or backplane) that the IO modules connect to. The IO modules are also redundant pairs, and just like the CPU's will hot swap in the event of a detected failure. Each carrier contains 4 Pairs (8 Cards), and each Logic Solver can contain up to 8 Carriers, although we chose to restrict this to 6. Each Redundant Pair of IO modules has 8 Channels. This means for a fully redundant Logic Solver, we can have 6x4x8 or 192 field devices connected.
Each CPU also has two network connections, one to the Primary Network and one to the Secondary Network. If a CPU loses its network, it will switch to its redundant pair.
There are also redundant power supplies, but these are irrelevant to this, and have not been shown for clarity.
So as you can see, there is already a high level of redundancy built into the hardware.
So What About the Networks
The diagram below shows the network configuration. Only 4 of the 9 Logic Solvers have been shown, and also in reality, the servers each have a pair of network connections, but we are only interested in the Logic Solvers, so to reduce the clutter, some of the server network links have been omitted.

The network topology is effectively a Twin-Star arrangement, one for the Primary and one for the Secondary network. Again, the switch redundancy means that an entire half of the system can be lost, and everything will continue to operate just fine. Additionally remember, each Logic Solver has 2 Primary and 2 Secondary networks, and in reality, you only need one network active to each Logic Solver and things will keep working.
The Engineering and Operator Workstations, and also the servers are connected to the same network.
Still Here? Time For Software
It is important how the software is structured, both for clarity, and maintainability. As we are looking at ESD systems, let's look at a very basic example. A Pressure Transmitter provides a signal which causes a valve to open when it sees a High High Pressure or a Low Low Pressure. There are also a number of other devices in the systems that can cause the valve to open. In addition to this, the operator can, if he or she chooses, open and close this valve.
Hang on, you said a basic example? It is, trust me; it will all become very clear.
What we do is break down the functional requirement into its component parts. Just like you do with software programming. This gives us an Input Module, a Logic Module, and an Output Module. Let's take a look at each one of these and discuss.
The Input Module
The Field Input block is where the real world device is read; this passes a value to the Alarm Block; set point values are compared against the process value, and if the set points are exceeded, alarms are raised and a Logic 1 is sent to the HH and LL Trip parameters as required. The override is normally off (Logic 0), and the Not block will mean a Logic 1 normally sits on the And blocks, and therefore allows the logic signals to reach the HH and LL Trip parameters. If an override is applied by the operator, a Logic 0 will appear at the And block, preventing the signals from reaching the Trip parameters, but still allowing the Alarms to function; after all, the operator still needs to know the trip condition exists, even if they don't want any executive action to occur.
It is important to note that at this stage, this module has done its thing, it is now up to any downstream module to read the logic states at the Trip parameters; this also means that any number of other modules can make use of this information, and can be added and removed as required, without ever having to modify the input module.
The Logic Module
The Logic Module (commonly known as Cause and Effect or C+E) takes care of what output events should occur for a given set of input conditions, and any number of output modules or other logic modules can hang off this module. So this module will read the upstream modules, do the necessary logic, in this case a simple OR, and pass this onto the downstream block, in this case a Latch. The Latch does as it suggests, and holds the Logic State at a Logic 1 on the output parameter, until such time that the operator decides he wants to reset the trip condition. As you can see in the example above, other C+E modules can provide reference parameters to be read for these logic inputs the same way as the transmitter is providing the HH and LL States for reading.
The Logic is always in a Logic 0 state for healthy. This means that modifications can be done to the logic with the system online, reducing the risk of interruption and accidental shutdowns.
The Output Module
The Output module is what connects the logic to the real world again. As you can see, there are a number of input parameters, and following the convention, these are read from the upstream modules and not written to by the upstream modules. The configuration of the OR blocks ensures that the ESD Logic and the Comms Fail Trip logic will always 'win' over what the operator demand is doing.
Now we are starting to see what we came for, the Comms Fail Trip has appeared at last. We will look at the Communications Failure mechanism in just a minute, but at this stage, all you need to know is that it is placed in the output module on its own input to the logic, to totally segregate it from all the other operator and Cause and Effect demands. And the configuration of the ORs mean that regardless of what the C+E or Operator wants, the fail safe Comms Fail Trip will always win and ultimately control the output device in the field.
As was stated in the above examples, the C+E modules can be cascaded as required in the system. You might have a very high level total shutdown logic, which cascades down to lower plant units in the chain, e.g., an individual pumps logic. The image below demonstrates what a basic cascade might look like:
But What About Communications Failure Detection?
Okay, we will look at that now!
As stated at the start, you can have any number of Logic Solvers in the system (limited by manufacturer's specification) and each Logic Solver will check each and every other Logic Solver to see if it is alive, or just like us, has a heartbeat. We have also noticed the Comms Fail Trip parameter located in every single output module.
So what we need to do is place a module that monitors the heartbeat of all the other logic solvers, whilst also generating its own heartbeat. We also need to make sure that every output module references the Comms Failure module located within the Logic Solver that hosts the output.
If we look back at the example system at the start that had 4 Logic Solvers, the module below is what we would place in Logic Solver #1:
The Signal Generator creates a square wave output which is read from the Hearbeat parameter by the other Logic Solvers.
The lower half contains the parameter reference to read the heartbeats from all the other logic solvers on the system. The heartbeat passes through a Positive Edge Trigger which sends a Logic 1 to the Retentive timers. The retentive timers are constantly trying to count up to 30 seconds (or whatever you choose). Every time a heartbeat is detected, the retentive timer is reset back to 0. If however the retentive timer reaches its target, a Logic 1 is sent to the Comms Fail Parameter providing the override is not switched on. The override is used to perform maintenance on the system. Now that the Comms Fail parameter is sitting at a Logic 1, every other module that references this parameter will enter the fail safe state, as shown in the output module example above.
The highest level C+E module on the system will also read this bit, so that the system not only triggers all its output to a fail safe state, but also initiates a logic shutdown which latches throughout the system, meaning when Comms are restored, everything remains in a tripped state until the operator chooses to perform the system resets.
Now, that wasn't too bad, was it? I hoped you enjoyed the brief introduction to Logic Solvers and implementing fail safe strategies.
Please feel free to leave comments below, or any other topics you would like to read about in the world of DCS.
Thanks for reading...
History
- 4th November 2010 - First release of article.



